8. Releases and use of unique identifiers
Learning Outcomes
By the end of this session, learners will be able to:
- Explain what unique persistent identifiers are and their benefits
- List and differentiate the types of unique identifiers that are relevant for publishing and sharing training materials
- Compare different strategies for unique identifiers for training materials
- Create versioned DOIs for training materials
8.1 Presentation
Here you can find the presentation for this session:
The full presentation can be viewed in Google slides or copied for reuse under a CC BY 4.0 license
8.2 Unique identifiers for training materials
What is a unique persistent identifier (PID)?
A persistent identifier (PID) is a long-lasting reference that uniquely tags a resource. PIDs are often used in the context of digital objects and are actionable, meaning that you can resolve them in a web browser and be taken to a webpage containing the digital object and its associated metadata. Actual access to the digital object on this page might be restricted, as a PID may be connected to a set of metadata describing an item rather than to the item itself.
The primary purpose of a PID is to provide the information required to reliably identify, verify, and locate the resource it is associated with. To achieve this, PIDs must comply with a few key principles:
-
Globally unique:
To ensure global uniqueness, a PID should follow a controlled syntax to avoid conflicts. This can be achieved for example by using namespaces that are governed by clearly defined authorities.
-
Persistent:
The identifier, and the object it points to, should be maintained over the long term. The syntax used for the identifier should also remain persistent.
-
Resolvable:
The identifier should allow both human and machine users to access the resource or its related information.
One of the most common PIDs used by public repositories is the Digital Object Identifier (DOI) (doi.org). DOIs are coupled with metadata that can be modified over time and to keep track of the locations and characteristics of the objects they identify. DOIs are generated automatically when you make your resources available in a repository such as Dataverse or Zenodo, or when a research article is published.
DOI relies on a non-profit organisation that is the governance body of the federation of registration agencies. If you would like to learn more about the concept of DOIs, take a look at this fact sheet.
Why are PIDs useful for training materials?
Using a public repository to assign a DOI to your training materials brings several benefits that align closely with the FAIR principles:
Findable (F):
DOIs make your resources uniquely identifiable, preventing confusion between similar materials. They also provide a structured place to store and manage metadata, which can be read by both humans and machines. Because DOIs are machine-actionable, they improve searchability and discoverability, helping others easily find your materials through search engines or automated systems.
Accessible (A):
Each DOI resolves to a landing page that contains information about the resource and how to access it. Even if the location of the actual file changes, the DOI will always direct users to the current metadata or resource, ensuring that access remains consistent over time.
Interoperable (I):
While a DOI itself does not automatically make a resource interoperable, the standardized metadata schemas (such as those provided by DataCite) help ensure that data and information can be shared and understood across different systems and repositories.
Reusable (R):
DOIs enhance citability and attribution, allowing others to reference your work accurately. Persistent identifiers support long-term tracking and recognition of your outputs, promoting reuse and helping your materials remain valuable and usable well into the future.
Other persistent identifiers useful for training materials
There are several types of PIDs designed for different kinds of resources or objects.
For training materials, the following PIDs are the most important:
-
ORCID
ORCID (Open Researcher and Contributor ID) provides a unique and persistent identifier for individual researchers, free of charge.
It helps distinguish between people with similar names (homonyms) and ensures that your work is correctly attributed to you, regardless of name changes or institutional moves. ORCID allows you to add aliases if your name changes, and your ORCID iD remains the same even when you change affiliations. This makes it a powerful tool for maintaining your research identity over time, ensuring that you always get proper credit and that your scholarly contributions are easy to track globally. -
ROR
The Research Organization Registry (ROR) is a global, community-led registry that assigns open persistent identifiers to research organizations. ROR helps systems and users unambiguously identify institutions and connect them to researchers and research outputs. For example, Science for Life Laboratory is often referred to as SciLifeLab. To avoid confusion between names, the SciLifeLab ROR ID uniquely identifies the organization, ensuring consistent and accurate affiliation metadata across platforms and publications.
Together, ORCID, ROR, and DOI form the foundation for making your training materials, their creators and institutions clearly identifiable, citable, and FAIR.
Reflection
In the context of training materials why are PIDs needed? Which identifier should be used for each need?
Answer
PIDs can help distinguish between:
- different materials - DOI
- different versions of the same material - DOI
- different authors and contributors - ORCID
- different oraginsations - ROR
Exercise
Go to the ROR search page and try to find your organisation’s ROR
8.3 Selecting a strategy for unique identifiers
DOI strategies for courses
Case Studies of Using PIDs in Training
Read through the real world examples of using PIDs in Training from FAIR handbook (chapter 05) (by ELIXIR training platform, CCBYSA 4.0 license), and answer the following questions in the chapter worksheet:
- Summarise the strategy used in each use case
- What is the main benefit with each strategy?
- Are there any drawbacks with each strategy?
You can make a copy of this course worksheet for reuse under a CC BY 4.0 license.
Case 1 - Assigning a unique DOI combined with ORCID for each event in a community
At Australian BioCommons, training materials from webinars and workshops are shared via a dedicated Zenodo community. BioCommons chose to use Zenodo to share training materials because they do not have a repository of their own, and Zenodo has established ways of managing metadata, DOIs and versioning. It is also widely used in the scientific community.
For each event, a Zenodo record is created that includes detailed metadata, new training materials and links to previous materials that were reused as part of the training (Figure 1).
Two types of PIDs are used when sharing materials from events:
-
DOIs - Zenodo automatically assigns a DOI to the event. DOIs are also used when linking to related materials to ensure that there is no ambiguity about which materials were used.
-
ORCID - Trainers’ ORCIDs are used to ensure that they get the credit for their efforts and to make it clear who participated in the event.
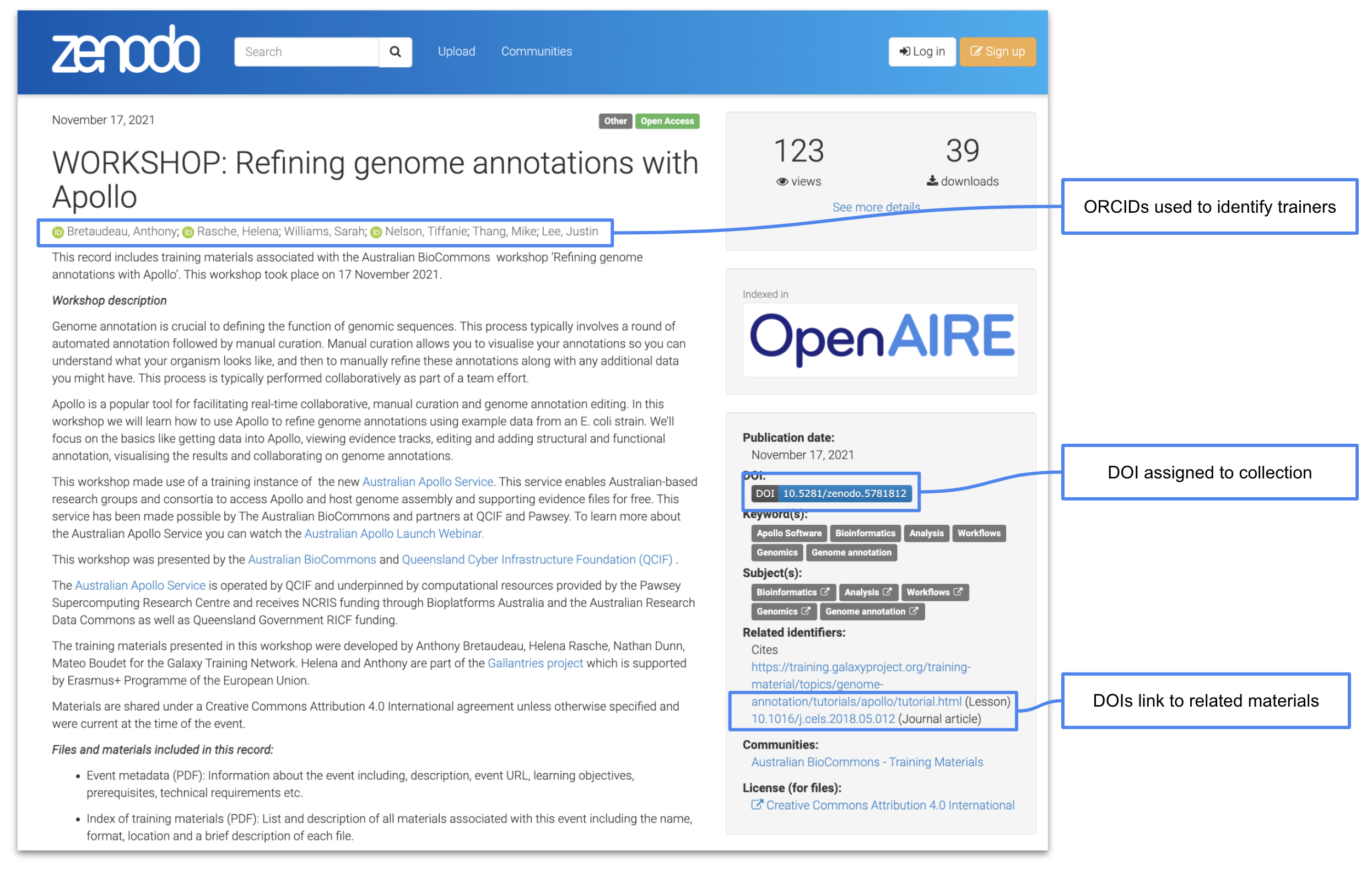
Figure 1: The Australian BioCommons collates materials from their events and shares them via Zenodo where they are assigned a DOI and authors are identified via their ORCIDs. View this record on Zenodo.
Case 2 - Creating virtual collections of training materials and assigning own PIDs
For CLARIN, a training event typically includes slides, handouts, a GitHub page, video tutorials, language resources, datasets, and/or tools. The slides and handouts are published on the event web page, while video recordings of the presentations are made available on the CLARIN YouTube channel. In addition, the language resources and tools used during the training are stored in CLARIN’s national repositories, where they are assigned unique identifiers by the hosting institutions, ensuring that they can be cited and reliably referenced.
One solution to have a PID assigned to all the materials used during one training event is to create a virtual collection in the CLARIN Virtual Collection Registry. A virtual collection is a coherent set of links of digital objects that can be easily created, accessed and cited with the help of PIDs, e.g. a DOI. The links can originate from different archives. Here is an example of a virtual collection created for a hands-on tutorial on transcribing interview data.
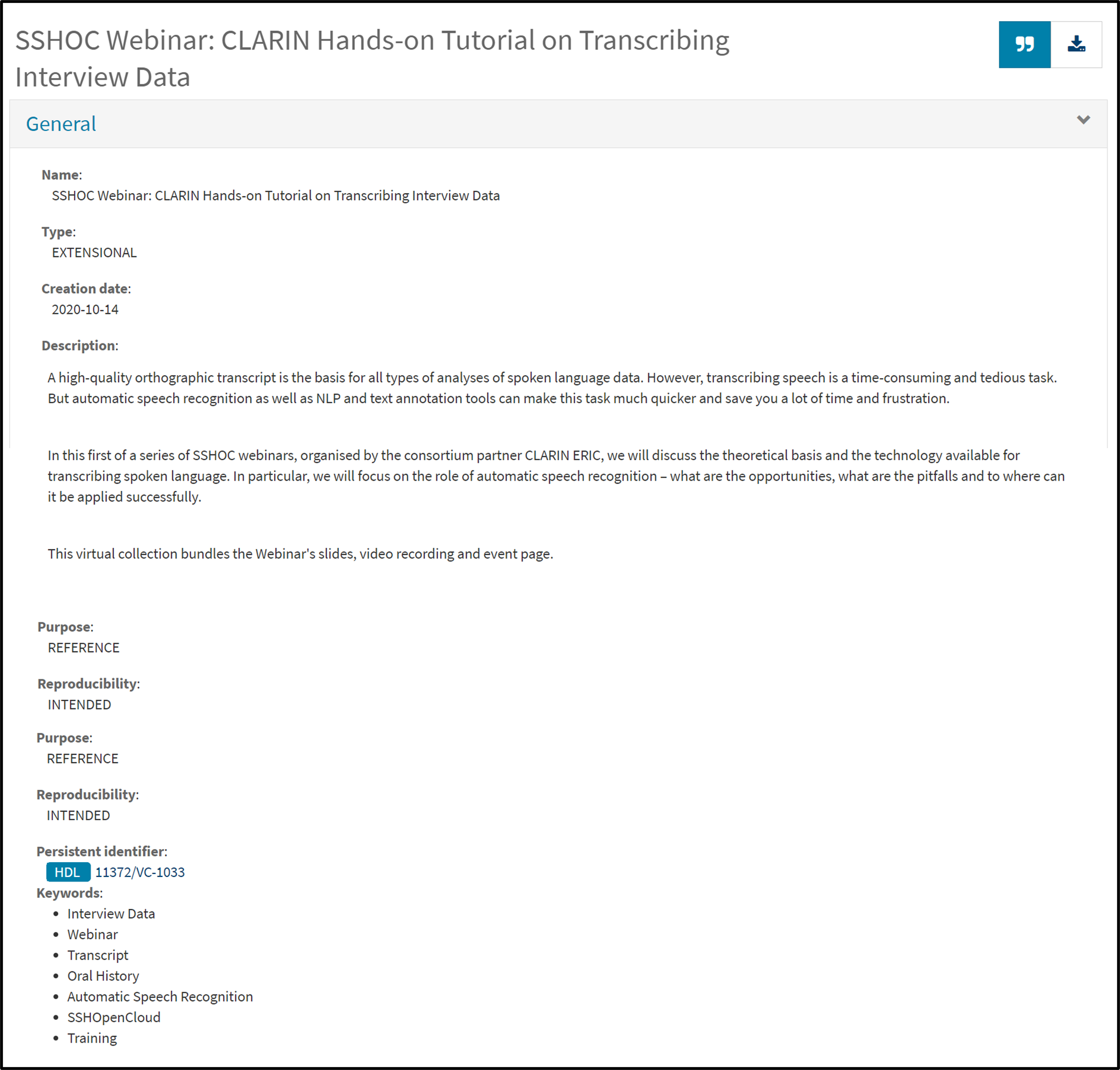
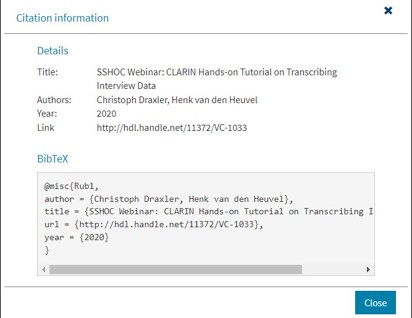
Figure 3: Example of a BibTeX citation in the CLARIN Virtual Collection Registry.
Other practices that the trainers in the CLARIN community have adopted are:
- Depositing the training materials together with the datasets in their CLARIN national data repository. See example: Archilochus of Paros: Elegiac Fragments - XML Archive. The advantage of using this path is that the authors can add more extensive metadata to describe their materials.
- Depositing the training materials on Zenodo. See example: Introduction to Speech Analysis. In this case, related identifiers are included that lead users to the main platform where the course is stored and maintained.
- Adding the metadata of the training materials to the SSHOC Open Marketplace, see example: Jupyter notebooks for Europeana newspaper text resource processing with CLARIN NLP tools. In this case, the Marketplace does not assign any unique identifiers, but the authors can identify themselves via their ORCID and can suggest a citation format for their collection.
Case 3 - Separate DOIs for mixing and matching in a community
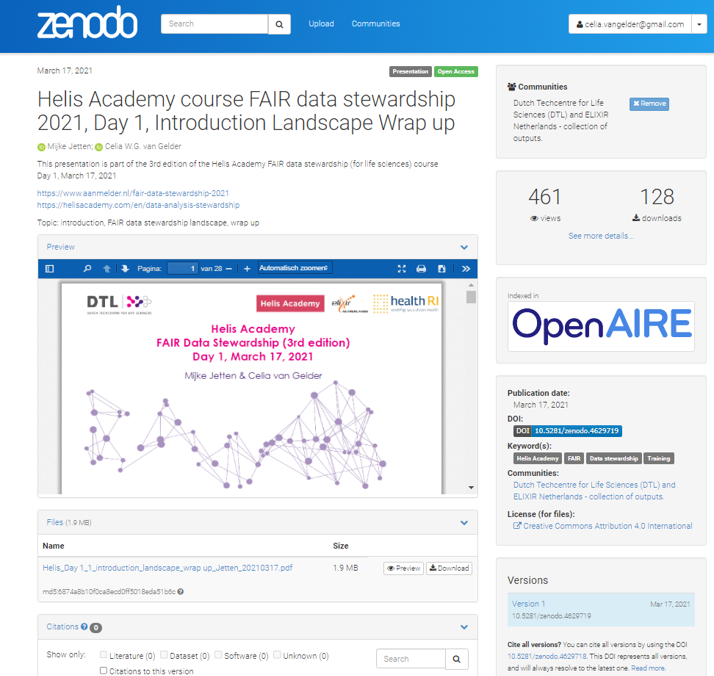
The Dutch Techcentre for Life Sciences (DTL) has a Zenodo community to upload presentations and course materials. DTL has chosen to give separate DOIs for individual, often topical, elements of a course. An example is the Helis Academy FAIR Datastewardship Course, a course of 6 half days.
Providing a separate DOI has the following advantages:
- It is easier to mix and match different modules as part of a learning path, i.e. different combinations of training modules can be made for the various target audiences, tailored to that specific purpose.
- When updating or revising a single module, it is more convenient to have that module as a separate entity with its own DOI, in order to easily keep track of the versions of different modules.
At the level of the full course, DTL uses ELIXIR TeSS as the registry. Links to training event details and training materials can be found here.

DOIs strategies for GitHub repositories and making use of releases to version training material
In this course we have promoted the use of GitHub for hosting markdown based training material. The public repositories Zenodo and Figshare integrate directly with GitHub to automatically issue DOIs for repositories. These integrations rely on GitHub releases, which are essentially snapshots of your project taken at a specific point in time. A release packages your project in a stable, downloadable form, making it easier for others to access and use. Each release is linked to a version number (for example, v1.0) and is created from a specific tag in your GitHub repository. Tags mark particular commits in the project’s history, allowing you and others to track the evolution of your work and see what has changed between versions.
In addition to tagging a release, you can add a title and release notes to include basic metadata that describes what has changed in that version. If you use Zenodo to archive your GitHub repository, the release notes are automatically imported as the record’s description, while some metadata fields are populated by default, e.g. Resource type is set to “Software” and a link to the GitHub repository is included under related works (or can be added manually if needed).
Each time you create a new release, a new version of your Zenodo or Figshare record is generated, and a new DOI is issued.
This DOI and the DOIs representing previous versions are automatically linked together, and an additional DOI is created to represent all versions of the record collectively. Read more about DOI versioning in Zenodo here.
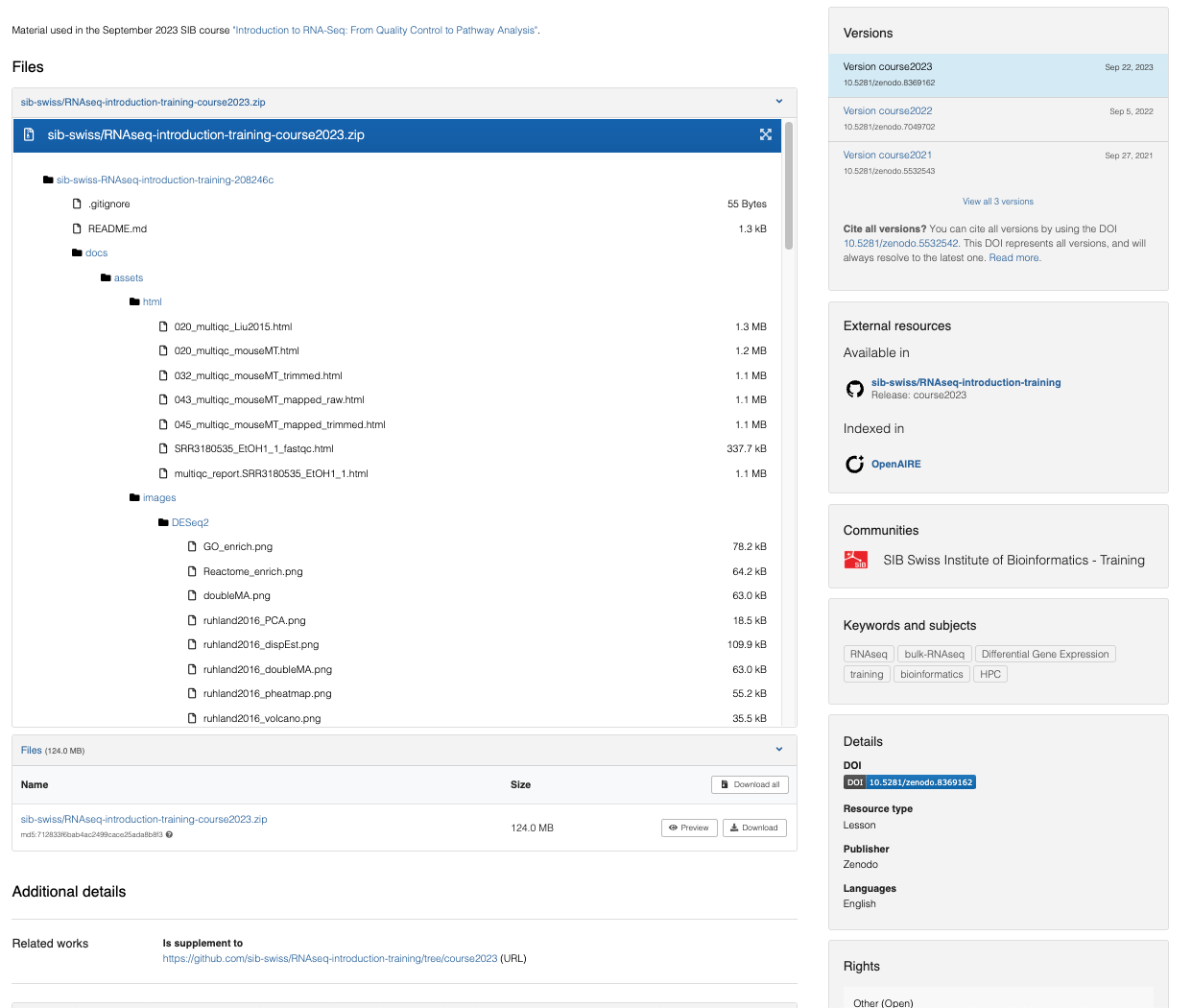
Figure 6: Example of Zenodo record for GitHub repository containing the training material for the SIB course Introduction to RNAseq… See more here.
Reflection
What could a good DOI strategy look like for your own context?
Things to consider
- Do you want to assign a DOI to each individual training material, such as a video, slide deck, or document?
- Would it be more useful to have one PID for the entire course or training package?
- If your course is divided into multiple topics or modules, would you prefer to assign a separate PID to each of them?
- Or would you rather create a collection PID that represents the whole course, while still assigning individual PIDs (and metadata) to each topic or component within it?
Read more in Chapter 5 of the FAIR Training Handbook
8.4 Tutorial for implementing your strategy
Now we will use Zenodo sandbox to create DOIs for our training material project from this course. A sandbox is used for testing purposes and DOIs created in the Zenodo Sandbox are not real and will not resolve. Choose the appropriate tutorial below based on the hosting platform you’ve used in the previous sessions.
Get a DOI for a GitHub repository
This tutorial will guide you through creating a Zenodo record for your GitHub repository that supports automatic versioning. Each time you create a new release of your repository, Zenodo will generate a new DOI that is linked to the original one. Before we get started, make sure you have the following accounts set up:
Get an ORCID
Register for an ORCID iD at the ORCID website
Get a GitHub account
If you don’t already have one, create a GitHub account by signing up here
Step 1- Link your repository to Zenodo
- Go to Zenodo Sandbox
- Sign up or sign in with your GitHub account
- Click the down arrow next to your
usernamein the top right corner to expand the menu, selectGitHubIf you have not used your GitHub account to sign in to Zenodo sandbox select
Linked Accountsfirst to connect your accounts - Find your repository in the list, toggle the switch to
ONIf your repository does not show up in the list, check when it was last synced in the title row of the first box and click
sync nowif needed - Reload the page > your repository should now be added to the list of
Enabled Repositories - Click on the repository to reach the Zenodo page of that repository > click
Create releasein the title row of theReleases boxYou have now moved to GitHub where we will create a release that will trigger an Zenodo record to be created.
Step 2 - Create a GitHub release of your repository
- Create a tag by clicking the
Select tagbutton in the top left part of the page. Enterv0.0.1in the text field and clickCreate new tag - Just below, enter
initial releaseas the Release title - In the large text box, add
This is the initial release of <Title of your training material>as release notes - Click the green button
Publish releaseA DOI record has now been created for your repository. Return to your Zenodo Sandbox > GitHub settings (see above) and inspect the list ofEnabled Repositories. A black and blue DOI badge should now be available next to your repository name. - To add the DOI badge to repository click the badge, in the popup window, copy the Markdown formatted text.
- Go to your GitHub repository and select your
readme.mdfile in the left side menu. Click the pen in the top right > paste the copied markdown text at the top of the file and commit your changes by clicking the green button in the top right corner Now it’s time to inspect the record and the metadata it contains. Return to your Zenodo Sandbox and clickDashboardin the middle of the top menu. Click on your record in the list and inspect the information in the record.
Reflection
Which metadata is automatically imported from your GitHub repository? Are there any important metadata fields that are missing?
Hints
Zenodo automatically extracts metadata about your release from GitHub APIs. For example, the authors are determined from the repository’s contributor statistics or the citation.cff file that is used to populate the GitHub repository with information. To overwrite some of the default metadata that would come from a regular GitHub release you can include a .zenodo.json file at the root of your GitHub repository. This will not be covered in this course but you can find more information in the Zenodo Developers documentation
| Zenodo Record | GitHub Repository |
|---|---|
| Description | release notes |
| Title | name of repository or citation.cff file if in place |
| Creators | citation.cff file if in place |
- Now, create a new release of your repository. This time, include the description of your Training material as release notes.
Step 3 - Add additional metadata to your record
Rich metadata is essential for making any digital object FAIR. In this step, we will manually add the metadata from the previous session to your Zenodo record for the repository.
- In your Zenodo Sandbox Dashboard, click
editnext to your repository in the list -
Set (change or add) the following:
Resource typeto “Lesson”Licenseto “Creative Commons Attribution 4.0 International aka CC-BY-4.0”Keywordsas specified previouslyFundingif any
-
In the
Creatorssection, clickeditnext to an existing name or click theAdd creatorbutton below the names. Make sure to add ‘Name’, ‘ORCID’ (under ‘identifiers’), and one or several ‘affiliations’. -
In the
Related Worksfield clickAdd related workto add a link to your TeSS record as follows:Relation: “Is described by”Identifier: “the url to your record”Scheme: “URL”Resource type: “Event”
-
Click
Save draftin the right side-menu and thenPreview. Review your record and if everything looks good, clickBack to editin the top left and thenPublishin the right side-menu.
Step 4 - Link your training material to your TeSS record through the DOI
The F3 principle of the FAIR data principles states that Metadata clearly and explicitly include the identifier of the data they describe. This principle also applies to training materials. To link your course description in TeSS with your course materials in a GitHub repository, include the DOI generated by Zenodo in the TeSS record (and in the repository) and link back to the TeSS record from Zenodo.
- Go to the test instance of TeSS
- Click
Editon your course record - Add the DOI in the designated field
Additional exercises
- Add a citation.cff file to your repository
- Add a .zenodo.json file to your repository. For an example see https://cdnis-brain.readthedocs.io/zenodo/
Get a DOI for material in a Google Drive folder
This tutorial will guide you through creating a Zenodo record for your training materials hosted on Google Drive. Please ensure you have an ORCID before starting.
Get an ORCID
Register for an ORCID iD at the ORCID website
Step 1 - Reserve a DOI on Zenodo
- Go to Zenodo Sandbox
- Sign up or sign in with your email adress or Github account
The ORCID connection might not be stable for Zenodo Sandbox
- Click the plus sign next to your
usernamein the top right corner to expand the menu - Select
New upload - Under
Basic informationgo through the mandatory fields one by one and set as follows:Do you already have a DOI for this uploadto “No”Resource typeto “Lesson”Titleto “Title of your Training material”Publication dateto “today’s date”Creatorsclick+ Add Creatorbutton and add your group members ORCIDs one at the timeDescriptionadd the course description formatted in a human readable wayLicenseto “Creative Commons Attribution 4.0 International aka CC-BY-4.0”
- Go back to the first field
Digital Object Identifier, click the buttonGet a DOI now!> This will reserve a DOI for your record that can be included in your files prior to upload. Copy the reserved DOI that has appeared to the left. It should look similar to this:10.5072/zenodo.109776 - Click
Save draftin the right hand menu
Step 2 - Upload your files
- Go to your Google Drive folder
- In your
readme file, add the DOI you reserved in the previous step - Now download the entire folder by right clicking on the folder name and then select
download. A.zip filewill de downloaded to your computer. - Locate the
.zip fileon your computer - Return to Zenodo Sandbox and in your Dashboard, click
editnext to your saved record in the list - Upload the
.zip fileyou downloaded from your Google Drive folder byDrag and dropor by clicking theUpload filesbutton - Click
Save draftin the right side-menu and thenPreview. Review your record and if everything looks good, clickBack to editin the top left and thenPublishin the right side-menu.
Step 3 - Add additional metadata to your record
Rich metadata is essential for making any digital object FAIR. In this step, we will manually add the metadata from the previous session to your Zenodo record for the repository. Adding or updating metadata does not create a new version of the record. A new version, and a new DOI, is only generated if you upload additional files to the repository.
- In your Zenodo Sandbox Dashboard, click
editnext to your repository in the list -
Set (change or add) the following:
Keywordsas specified previouslyFundingif any
-
In the
Related Worksfield clickAdd related workto add a link to your TeSS record as follows:Relation: “Is described by”Identifier: “the url to your record”Scheme: “URL”Resource type: “Event”
-
Click
Save draftin the right side-menu and thenPreview. Review your record and if everything looks good, clickBack to editin the top left and thenPublishin the right side-menu.
Step 4 - Link your training material to your TeSS record through the DOI
The F3 principle of the FAIR data principles states that Metadata clearly and explicitly include the identifier of the data they describe. This principle also applies to training materials. To link your course description in TeSS with your course materials, include the DOI generated by Zenodo in the TeSS record (and in the repository) and link back to the TeSS record from Zenodo.
- Go to the test instance of TeSS
- Click
Editon your course record - Add the DOI in the designated field
Additional exercises
- Add a link to your LMS in the
Related Worksfield. Determine appropriate values for the following fields:RelationIdentifierSchemeResource type