5. Get a persistent identifier for your training material
Checklist
5.1 Give your training material a PID, e.g. a DOI.
5.2 Give yourself a PID, e.g. an ORCID.
5.3 Add these unique identifiers to the training materials metadata.
Description
In this chapter, we present what a persistent identifier (PID) is, and how to get one for your training materials. This step is essential to achieving FAIR training materials, as it is directly linked to Findability and Reuse. By getting a PID, the visibility of your work is enhanced, and the associated deposit works as a backup of your work by handing over the maintenance to the designated repository.
Learning outcomes
At the end of this chapter you should be able to:
- Explain what a PID is and its importance for enabling and sharing training resources in the context of FAIR and open education and training.
- List and differentiate the types of PIDs that are relevant for publishing and sharing training materials.
- Assign an appropriate PID to your training materials.
- Get an author ID ORCID.
Prerequisites
Before you start with this chapter, we recommend that you first read:
* Chapter 2- Structure materials for FAIRness
* Chapter 3- Getting ready to create your materials
These chapters will help you to structure your training materials, find a suitable storage location, and think about collaborators and potential readers. This knowledge will then help you to decide whether you need to assign each material its own identifier or organise the entire collection under one identifier.
What is a Persistent Identifier (PID) and why should I use it for training materials?
Open science seeks to improve the sharing of a large body of knowledge on a wide scale. To facilitate this, it is necessary that each element to be shared can be easily and unambiguously identified and retrieved. The solution to this challenge is to assign each piece of information (training material, data, software, document, author etc.) a unique and permanent identifier (PID: Persistent Identifier).
Imagine the following scenario: If you go to the opera, you leave your coat in the cloakroom in exchange for a ticket. From that moment on, you don’t have to worry about where your coat is stored. You enjoy the performance, knowing that your ticket allows you to get your coat back. This ticket carries a unique identifier (a number on the ticket) issued by a trusted third party (the wardrobe attendant) who makes sure that this number is unique and remains assigned to your coat.
In the same way, having a persistent identifier for training materials makes them easier to find among all the other materials in the same repository (i.e., the cloakroom). Furthermore, this facilitates long-lasting material accessibility as backup. Using PIDs for authors also makes it easier to identify and acknowledge individual contributions to developing and maintaining the materials. This makes the materials easier to cite when it comes to reusing them.
The PIDs must comply with a few rules:
-
Globally unique:
To enable global uniqueness, a PID should comply with a controlled syntax to avoid clashes, for instance, by having namespaces that are governed by clearly defined authorities. (the number of your ticket is unique, so you are sure you will get your coat back and not someone else’s)
-
Persistent:
The identifier, and the object to which it points, should be maintained for a long period of time. The syntax used for the identifier should be also persistent (don’t change the way you label your tickets; don’t dispose of the coat during the opera).
-
Resolvable:
The identifier allows both human and machine users to access the resource (the ticket tells you where to get your coat back).
By now you must be asking: in the context of training, for what do I need PIDs? Let us help you with that! For training materials, PIDs can be assigned to:
- Individual training materials (e.g., a set of slides, a training dataset)
- A collection of materials associated with a training event or topic
- The authors of the materials
In the following sections, we discuss how to get these PIDs for your training materials. Some real-world case studies provide a few examples of approaches to giving PIDs to your training materials.
Types of PIDs relevant for training materials
Although many different PID types can be applied to objects and authors, here we will focus only on the ones that are most often assigned to training materials, namely DOIs and ORCID.
What is a DOI?
If you want to share your training material with the rest of the world, we recommend using a Digital Object Identifier (DOI) (doi.org). DOIs are one of the most common PIDs used by public repositories. If you would like to learn more about the concept of DOIs, take a look at this fact sheet. DOI stands for Digital Object Identifier, and it is a unique, persistent and permanent identification of objects (physical or digital). And as DOIs are coupled with metadata, they can be modified over time to keep track of the locations and characteristics of the objects they identify, both for you and your users. You benefit from efficient management and accurate tracking, as well as gaining the ability to more easily automate processes and collaborate with partners in your community. DOI relies on a non-profit organisation that is the governance body of the federation of registration agencies. DOIs are generated automatically when you make your resources available in a repository such as Dataverse or Zenodo, or when a research article is published.
What is an ORCID?
ORCID, which stands for Open Researcher and Contributor ID, is a global, non-profit organisation which provides a unique and persistent identifier free of charge to researchers. Especially if you have a common name, you’ll know how important it is to distinguish homonyms! It is extremely useful to be correctly identified, worldwide. ORCID takes homonymy into account, and the system also allows you to add aliases to your profile in the event that your name changes, making sure that it will be tracked back to you. Another benefit is that your ORCID will stay the same, even when your affiliation changes, ensuring that you get the credit you deserve and helping you keep track of your work.
You can watch the video below for more information.
What is ORCID? from ORCID on Vimeo.
As you can see, PIDs for authors make it much easier to Find materials written by a particular person, and also make it easier to ensure the credits for the right person. The Open Researcher and Contributor ID (ORCID) is increasingly used by journals and funders to uniquely identify individuals. It is already a requirement at the NIH (National Institutes of Health), CDC (Centers for Disease Control and Prevention), and more than 110 publishers. Therefore, it is a good option for authors of training materials as well.
Get yourself an ORCID
Watch the video below to learn how to get your own ORCID.
A Quick Tour of the ORCID Record from ORCID on Vimeo.
Exercise
Learning experience: Read the case studies below to see some examples of how PIDs are used for training materials. Afterwards, think critically about your material and which case would fit your needs better. You can write down your ideas, create a schema, etc.
Info
Customised Persistent IDs, Pros & Cons:
To be updated - What is it - How to do it - Pros & Cons
How does it work in the real world: Case Studies of Using PIDs in Training
Before explaining how to assign PIDs to training materials, we would like to show you some illustrations of how organisations are approaching this in practice.
1. Assigning a unique DOI combined with ORCID for each event in a community
At Australian BioCommons, training materials from webinars and workshops are shared via a dedicated Zenodo community. BioCommons chose to use Zenodo to share training materials because they do not have a repository of their own, and Zenodo has established ways of managing metadata, DOIs and versioning. It is also widely used in the scientific community.
For each event, a Zenodo record is created that includes detailed metadata, new training materials and links to previous materials that were reused as part of the training (Figure 1).
Two types of PIDs are used when sharing materials from our events.
-
DOIs - Zenodo automatically assigns a DOI to the event. DOIs are also used when linking to related materials to ensure that there is no ambiguity about which materials were used.
-
ORCID - Trainers’ ORCIDs are used to ensure that they get the credit for their efforts and to make it clear who participated in the event.
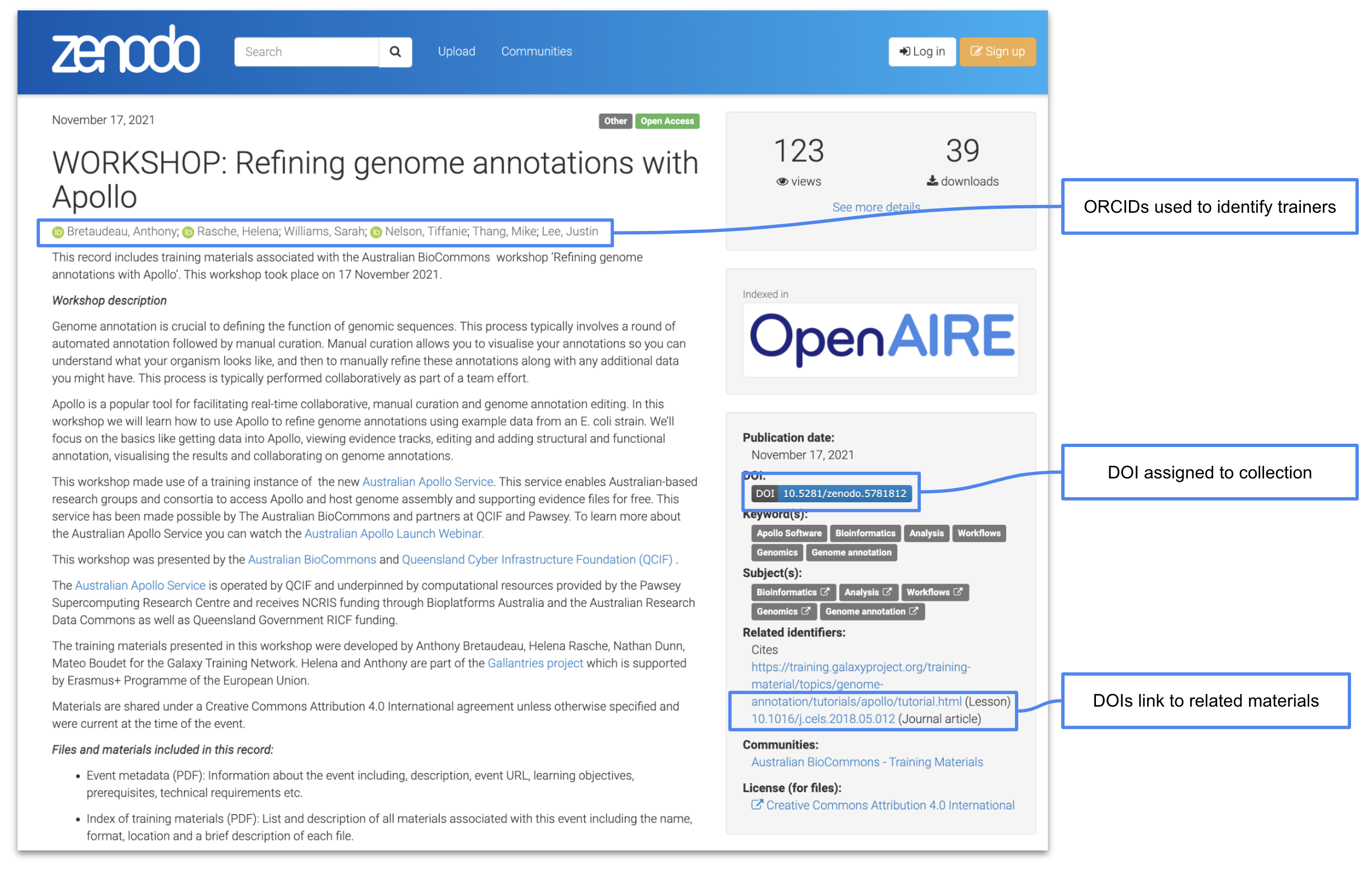
Figure 1: The Australian BioCommons collates materials from their events and shares them via Zenodo where they are assigned a DOI and authors are identified via their ORCIDs. View this record on Zenodo.
2. Creating virtual collections of training materials and assigning own PIDs
For CLARIN, a training event usually consists of slides, handouts, a GitHub page, video tutorials, language resources, datasets and/or tools. The slides and handouts are published on the event web page, while the video recordings of the presentations are published on the CLARIN YouTube channel. In addition, the language resources and tools used during the training are stored in the CLARIN national repositories, with a unique identifier assigned by the institution and can be cited.
One solution to have a PID assigned to all the materials used during one training event is to create a virtual collection in the CLARIN Virtual Collection Registry. A virtual collection is a coherent set of links of digital objects that can be easily created, accessed and cited with the help of unique identifiers, for example, a DOI. The links can originate from different archives. Here is an example of a virtual collection created for a hands-on tutorial on transcribing interview data
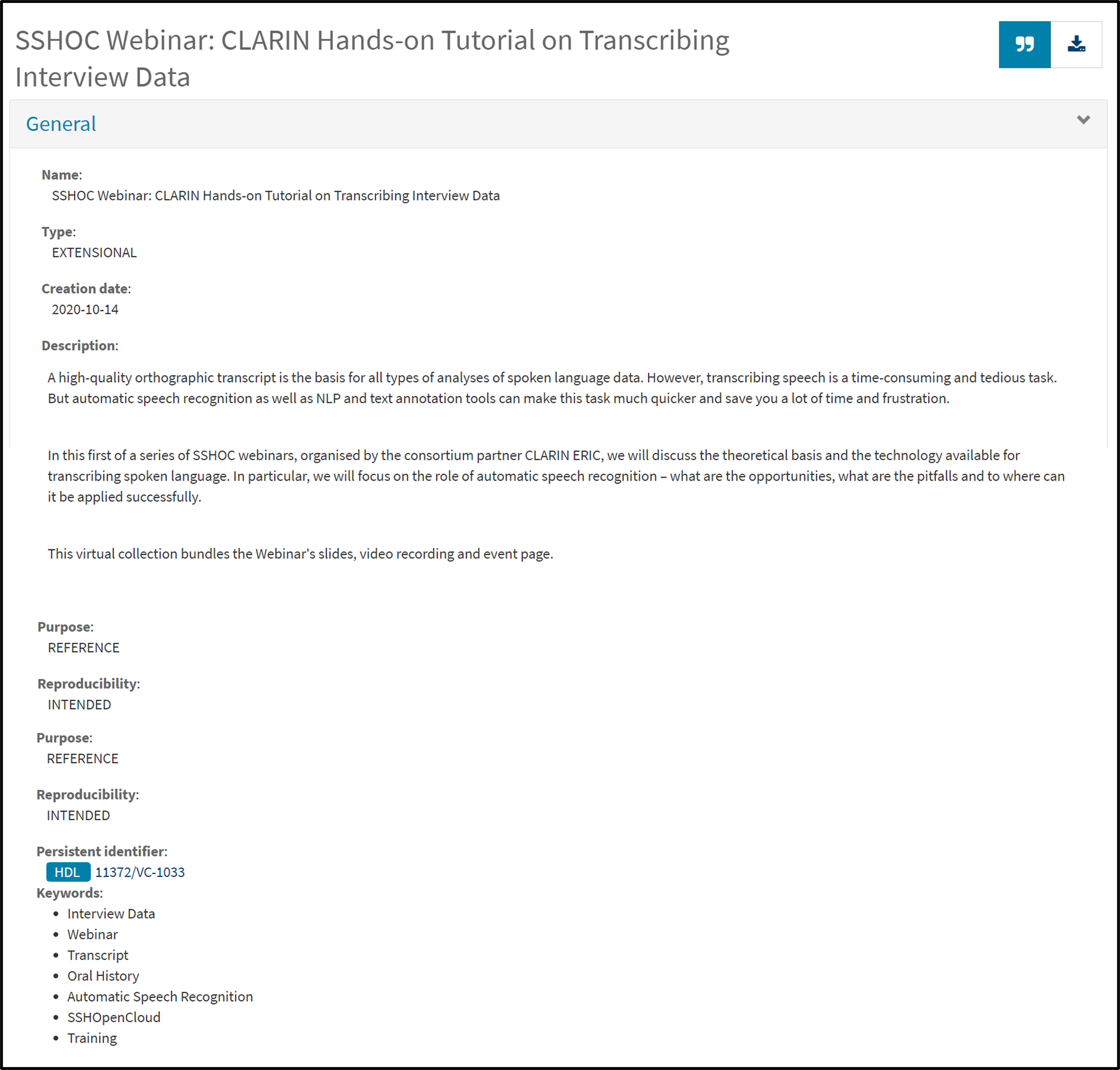
Figure 2: Example of a training collection in the CLARIN Virtual Collection Registry that has been assigned a persistent identifier.
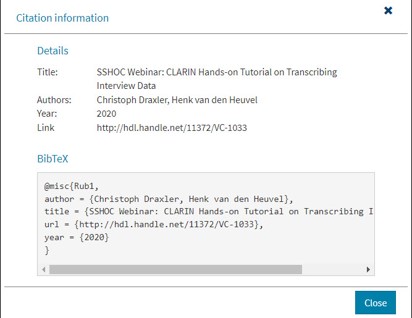
Figure 3: Example of a BibTeX citation in the CLARIN Virtual Collection Registry.
Other practices that the trainers in the CLARIN community have adopted are:
- First, depositing the training materials together with the datasets in their CLARIN national data repository. See example:Archilochus of Paros: Elegiac Fragments - XML Archive. The advantage of using this path is that the authors can add more extensive metadata to describe their materials.
- Second, depositing the training materials on Zenodo. See example: Introduction to Speech Analysis. In this case, related identifiers are included that lead users to the main platform where the course is stored and maintained.
- Third, adding the metadata of the training materials to the SSHOC Open Marketplace, see example: Jupyter notebooks for Europeana newspaper text resource processing with CLARIN NLP tools. In this case, the Marketplace does not assign any unique identifiers, but the authors can identify themselves via their ORCID and can suggest a citation format for their collection.
You can do the same by using Zenodo, for example, by publishing and assigning a DOI not only to the entire training collection, but also to each item in the collection, as can be seen in the next example.
3. Sparate DOIs for mix and matching in a community
The Dutch Techcentre for Life Sciences (DTL) has a Zenodo community to upload presentations and course materials. DTL has chosen to give separate DOIs for individual, often topical, elements of a course. An example is the Helis Academy FAIR Datastewardship Course, a course of 6 half days.
Providing a separate DOI has the following advantages: It is easier to mix and match different modules as part of a learning path, i.e. different combinations of our training modules can be made for the various target audiences, tailored to that specific purpose. When updating or revising a single module, it is more convenient to have that module as a separate entity with its own DOI, in order to easily keep track of the versions of different modules.
At the level of the full course, we have chosen to use ELIXIR TeSS as the registry. Links to our training event details and training materials can be found here.

Figure 4: Example from the DTL Helis FAIR Data Stewardship Course with separate DOIs per topic. See more here.
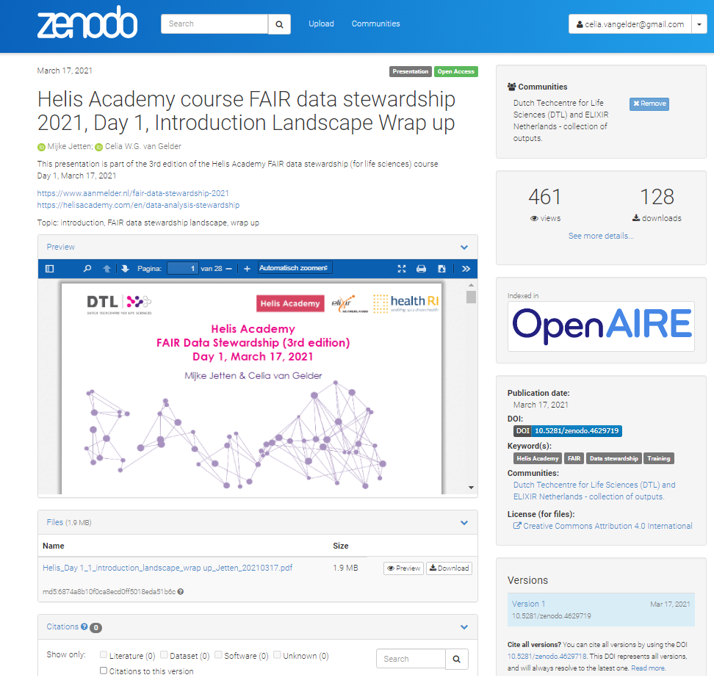
Figure 5: Zenodo record for the Introductory Module of the DTL FAIR Data Stewardship Course. View this record on Zenodo.
How to get a DOI for your training materials
Before getting a PID for your training materials, you need to think about how you want to organise your materials and how extensive your collection is. To help, ask yourself the following:
- Do you want to get a PID for each training material?
- Do you want to get one PID for your whole training or course?
- Do you want to get a separate PID for each topic/module? For example, for a course containing several topics.
- Do you want to create a collection of topics with a PID where each concept will also have a PID and associated metadata?
- Do you want to get one PID for your whole training or course?
All questions are valid, you just need to make sure that when you share the materials, all related data will be findable, accessible and reusable as much as possible. With that in mind, you might want to find a strategy to help others reuse your training materials if they are very extensive. For example, a full day’s or a full week’s training event may consist not only of presentations, but also a description of each session, activities, videos, etc. So in this case, it could be handy to split the training into smaller sessions with individual PIDs, which can then be packaged into a collection.
By far the easiest way to get a PID for your training materials is by sharing them in a public repository that assigns a PID on your behalf. You can learn more about this in RDMkit and Chapter 2 and Chapter 3.
For example, in the case study you read earlier, the Australian BioCommons shared materials via Zenodo, which automatically assigns a DOI to the materials. Similarly, the CLARIN Virtual Collection Registry assigns a PID (either Handle or DOI) to materials added to a virtual collection. If you are sharing your materials via GitHub, you also have the option of using Zenodo to archive your repository on GitHub and issue a DOI for the archive.
However, if you are maintaining your own repository of training materials, you will need to have a system in place for assigning and maintaining persistent identifiers. RDMkit provides guidance on the issues you will need to consider when doing this.
How to choose a repository
Do you need help in choosing a repository for your materials? Take a look at this advice in Chapter 3.
Exercise
Activity: Go to your favourite repository and check: a. Do they use DOI? b. If not, what kind of identifier do they use? Is it a Persistent identifier?
Evaluate yourself
Now you have completed the chapter, you should have reached the learning outcomes. Can you explain why PIDs are important for training materials? What is your plan for assigning PIDs to your own materials?

Please give us your feedback, we are always working on improving this book to attend the needs of its users. When writing your feedback please add the chapter number or name. Thank you.