1. Why FAIR training & training materials?
Checklist
1.1 Congrats, by reading so far, you are already making the first steps to make your training materials FAIR. Just keep reading the rest of the handbook.
Description
In this chapter we explain what the FAIR principles are, the importance of these principles and their increased adoption over the years, as well as the pros and cons of making training materials FAIR. We will give a brief history of FAIR data, and how these principles were extended and adapted to training materials.
Learning outcomes
At the end of this chapter you should be able to:
- Explain what FAIR means
- Describe the difference between FAIR and Open
- Determine whether a given type of training material can in principle be FAIRifyed
- List the main pros and cons of FAIRifying training materials
Prerequisites
None, except the interest to continue reading further.
The FAIR Data principles in details
Preparing training materials is a fundamental step in developing new training sessions, which is time-consuming and demanding for both new and experienced trainers. One approach to solving this issue is by finding and (re)using already existent materials. However, it requires that the authors of these have shared, properly described, and made these available for (re)use. It can be difficult to locate online resources that are appropriate for your teaching goals and that don’t have licence or copyright constraints. They frequently lack the necessary metadata to permit their (re)use, are dispersed across numerous repositories, or are compartmentalised within their original institutions.
The FAIR data principles, which stand for findable, accessible, interoperable, and reusable, were released in 2016 . The purpose of the FAIR Data Principles is to increase the value of data by making it simpler to find through the use of unique identifiers and simpler to combine and integrate through the use of formal shared knowledge representation. They were created to be understood/applied not only by humans but also by machines, in an automated way. Training materials are data as well, and as for any digital object, by applying and adopting the FAIR principles, we are adding value to them.
Initial considerations for applying FAIR principles to training materials
First things first: what is a training material, and which training materials should you consider making FAIR? Well, a simple definition of training material is anything you would produce yourself (or reuse) as support for your teaching activity. These can be slides, datasets, videos, software, a GitHub repo, a collection of exercises, VMs/Containers, etc. In summary, any digital object which can be used to deliver a lesson, course or curriculum. In Chapter 2, we further describe types of materials and their levels of FAIRness as well.
In 2018, a community of educators, trainers and training facilitators formed the ELIXIR FAIR Training focus group, which started the exercise of reflecting on what would be needed (what would it take) to make training FAIR and thus training materials FAIR. The result of this community exercise was published in the PLoS Computational Biology Ten Simple Rules collection with the paper 10 Simple Rules for Making Training Materials Findable, Accessible, Interoperable and Reusable (FAIR) 1. which is summarised in Figure 1. Overall, the rules were defined to help instructors and training facilitators make their first steps into making training materials FAIR, enabling others to find, (re)use, and adapt them. Much water has flowed under the bridge since then, and many people have tried to FAIRify (at least partially) their materials, and we still see and feel that it’s not so simple to do all the steps at once.
But if this is not so simple, why should we care to make training materials FAIR? The main reason behind it is to share. The more we share training materials, the more we spread our knowledge with trainers, and by sharing, we are giving back to the community in a virtuous circle. Going beyond this magnanimous idea, we can improve our course content based on the feedback we receive from peers and learners, and we can also learn from them and progress. By sharing, we provide inspiration for other trainers on how to run an exercise or how we explain a concept in our lectures, in the same way that we get inspiration from others, from books or websites.
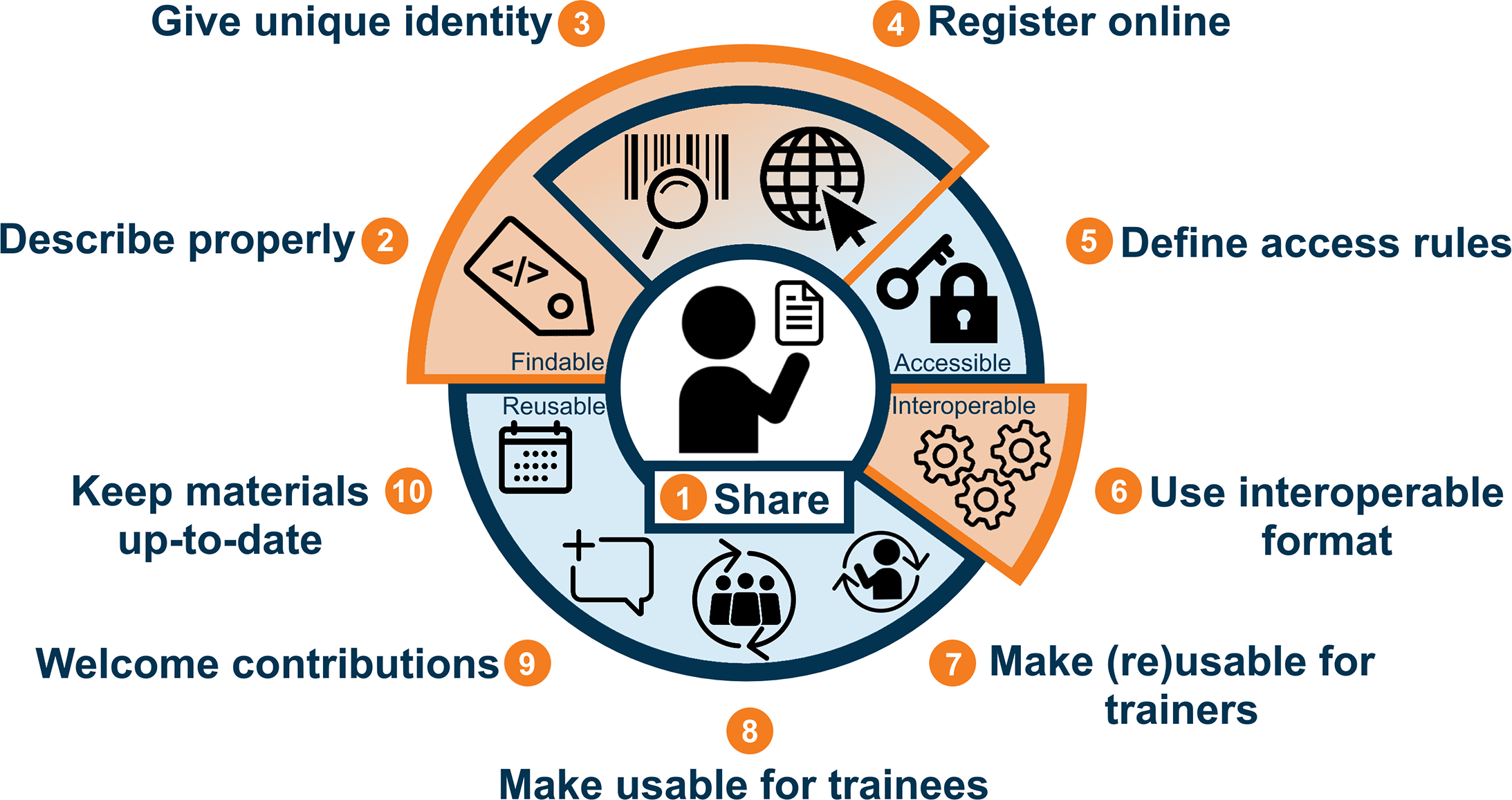
Figure 1: Ten simple rules for making training materials FAIR. Reproduced under CC-BY-SA 4.0 from Garcia et al1.
Today, sharing training materials is not an issue anymore because a vast data ecosystem is available. However, training materials are very diverse and less integrated, which makes it harder for both computers and human beings to find them, and for humans to reuse them. Today, a quick web search can help us find videos (on YouTube), presentations (in Zenodo or FigShare), and whole course materials (on GitHub, in decentralised institutional websites, or open globally-scoped repositories). Given that these repositories accept a wide range of data types in a wide range of formats and impose minimal limits (or criteria) on the descriptors of the data deposition, it can be difficult to determine the context in which the content was created or used (for which course, which audience), and thus being able to reuse it.
Consider the following example in the domain of single-cell omics training to obtain an idea of the obstacles faced. A search in TeSS (the ELIXIR’s Training portal) material session using the expression “single-cell” will generate a list of a minimum of ten items - they are thus Findable. The difficulty is to know which ones can be used and in which context. They are therefore Findable but may not be Accessible or Accessible under a restrictive licence which would not allow you to Reuse them in your teaching context. And if they are Accessible, they may be in a format that requires specific software that requires a paid licence as well, for instance, an exercise in Matlab, which makes Interoperability more difficult or impossible if you don’t have that licence.
Findable, Accessible, and Reusable are three principles that one can intuitively and easily visualise their application for training materials. Interoperability is a little less but becomes less mysterious when we reflect on training material formats, and the interoperations trainers or learners can do to reuse them. We must note however that the FAIR principles were depicted to be followed/applicable by humans and machines. Even though it’s difficult to imagine a machine reusing your training materials to teach, we need the machines to facilitate and interface F, A, I and R. The following paragraph, copied/pasted from the FAIR principles , can further shed some light on our reflections:
Humans and machines often face distinct barriers when attempting to find and process data on the Web. Humans have an intuitive sense of ‘semantics’ (the meaning or intent of a digital object) because we are capable of identifying and interpreting a wide variety of contextual cues, whether those take the form of structural/visual/iconic cues in the layout of a Web page, or the content of narrative notes. As such, we are less likely to make errors in the selection of appropriate data or other digital objects, although humans will face similar difficulties if sufficient contextual metadata is lacking. The primary limitation of humans, however, is that we are unable to operate at the scope, scale, and speed necessitated by the scale of contemporary scientific data and complexity of e-Science. It is for this reason that humans increasingly rely on computational agents to undertake discovery and integration tasks on their behalf. This necessitates machines to be capable of autonomously and appropriately acting when faced with the wide range of types, formats, and access-mechanisms/protocols that will be encountered during their self-guided exploration of the global data ecosystem. It also necessitates that the machines keep an exquisite record of provenance such that the data they are collecting can be accurately and adequately cited. Assisting these agents, therefore, is a critical consideration for all participants in the data management and stewardship process—from researchers and data producers to data repository hosts.
Exercise
Reflect on the FAIR principles and with your own words and examples, explain what are the FAIR principles and how they can be applied to your training materials.
Exercise
Reflect on your training materials or those that you have used at school as a child. List 2-3 examples of materials that cannot be FAIRified.
FAIR vs OPEN
Even though the expressions FAIR and Open are very frequently used as synonymous by many, we will see that they are not. Open Science started as a movement aiming to make scientific research – in the broadest sense, i.e. including publications, data, software, and educational resources – openly accessible to the public. Other related terms are Open Access and Open Data. Open Access is the term that relates to publications. It aims to give researchers, students, and the interested public free and immediate access to scholarly publications.
Open Data aims to encourage sharing data and code on repositories to make research results transparent and reproducible. However, paraphrasing the GO-FAIR consortium: FAIR does not necessarily mean OPEN. The FAIR principles enable something to be as open as possible and as closed as necessary. The level of openness defined in a data access licence affects the accessibility (A) of the data but not F, I, or R.
The following is an interesting explanation from the GO-FAIR consortium that will help you understand why FAIR is not equal to Open:
The ‘A’ in FAIR stands for ‘Accessible under well defined conditions’. There may be legitimate reasons to shield data and services generated with public funding from public access. These include personal privacy, national security, and competitiveness. The FAIR principles, although inspired by Open Science, explicitly and deliberately do not address moral and ethical issues pertaining to the openness of data. In the envisioned Internet of FAIR Data and Services, the degree to which any piece of data is available, or even advertised as being available (via its metadata) is entirely at the discretion of the data owner. FAIR only speaks to the need to describe a process – mechanised or manual – for accessing discovered data; a requirement to openly and richly describe the context within which those data were generated, to enable evaluation of its utility; to explicitly define the conditions under which they may be reused; and to provide clear instructions on how they should be cited when reused [11]. None of these principles necessitate data being “open” or “free”. They do, however, require clarity and transparency around the conditions governing access and reuse. As such, while FAIR data does not need to be open, in order to comply with the condition of reusability, FAIR data are required to have a clear, preferably machine readable, license. The transparent but controlled accessibility of data and services, as opposed to the ambiguous blanket-concept of “open”, allows the participation of a broad range of sectors – public and private – as well as genuine equal partnership with stakeholders in all societies around the world.
To contextualise the GO-FAIR consortium paragraph above, you can imagine that several universities, institutions, companies or countries worldwide still have institutional or national regulations that stipulate that in-house products should remain within their walls and are only accessible internally. In this case, training materials produced by their professors and instructors’ employees should remain their property, and only internal access would be granted to their students, learners, and citizens. These materials are thus not Open, but they can still be FAIRifyed to benefit these internal users and your reusability as a trainer. By FAIRifying training materials, we are also documenting how and when they were used, which can be handy to refresh our minds later when we teach the same content again and as a good practice in data management as well.
Exercise
Write down the main difference between Open and FAIR.
Evaluate yourself
Now that you have completed the chapter, you should have reached the learning outcomes. Scroll up, and see whether you managed.

Please give us your feedback, we are always working on improving this book to attend the needs of its users. When writing your feedback please add the chapter number or name. Thank you.
-
Leyla Garcia, Bérénice Batut, Melissa L. Burke, Mateusz Kuzak, Fotis Psomopoulos, Ricardo Arcila, Teresa K. Attwood, Niall Beard, Denise Carvalho-Silva, Alexandros C. Dimopoulos, Victoria Dominguez del Angel, Michel Dumontier, Kim T. Gurwitz, Roland Krause, Peter McQuilton, Loredana Le Pera, Sarah L. Morgan, Päivi Rauste, Allegra Via, Pascal Kahlem, Gabriella Rustici, Celia W. G. van Gelder, and Patricia M. Palagi. Ten simple rules for making training materials fair. PLOS Computational Biology, 16(5):1–9, 05 2020. URL: https://doi.org/10.1371/journal.pcbi.1007854, doi:10.1371/journal.pcbi.1007854. ↩↩